How To Manage Multiple Domains With Identical Content From Being Removed/Penalized By Google New Anti-Spam Rules
Hitbox Professional tracking data for Robin Good's masternewmedia.org domain
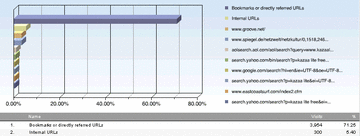
Click the image to enlarge it
Every person who has a Web site and wants to achieve good exposure and significant reach works hard to make sure that Google indexes the Web site in question so that it can be found and visited by as many people as possible.
On this site, not more than 6 months ago I had close to 80% of my Web traffic coming from the major search engines and mostly from Google itself.
In that light, loosing my presence inside the Google index would be quite a loss and one that if one was doing real business online could be very costly too.
I have therefore long been worried, together with my technology guru and webmaster about the fact that Robin Good's official site, accessible both at http://www.masternewmedia.org/ and at http://www.masternewmedia.com/ would be at some point be penalized for having one unique IP point to two different domains with the exact same content.
Since mine was not an attempt to gain extra exposure, better ranking or to increase my Pagerank, I have conforted myself thinking that though this would appear ambiguos to search engines checking for duplicate content or domains I was not really doing anything unethical (at least from my point of view).
Even recently I questioned the issue again with my stuff as the problem was now influencing also my Hitbox live traffic tracker who had been set to monitor and report visitors to my masternewmedia.org pages and which in fact would not report or calculate all of those visitors that instead are coming to my site by landing on the .com domain. This happens mostly because Google has indexed my pages sometimes using the .com URL for an article, and some other times using the .org. So I do get visitors arriving in significant quantity at both domains.
Even Daniel Brandt of Google-Watch recently wrote to me about the issue to unearth with me some interesting aspects of this.
Daniel Brandt wrote:
-----Original Message-----
From: xxxx@google-watch.org [mailto:xxxx@google-watch.org]
Sent: mercoledì 25 giugno 2003 3.22
To: xxxx@ikonosnewmedia.com
Subject: Question about masternewmedia sites
Dear Robin Good aka Mr. Luigi Canali De Rossi:
I have a question about your two masternewmedia sites, the .com site and the duplicate .org site.
How do you keep Google from dumping one of the duplicate sites?
I became interested in your work from my research on Google's faults.
You linked to my name on May 30, to a page that had zero content as far as Google was concerned. The only content was the phrase "Back to home page" and the rest of the content was embedded in a GIF image, which Googlebot did not fetch and cannot read.
Yet today I noticed that in a search for "daniel brandt" (without the quotes), this page at www.google-watch.org/staffbl.html came up number one or two, out of 178,000 hits. It was all due to the fact that the words "daniel brandt" were in the anchor text on your two masternewmedia sites. These words are not associated with the page elsewhere.
I don't mind, obviously, and I rather like the work you're doing compared to other bloggers I've criticized at GoogleWatch. But I was curious about how you got away with two duplicate sites, each of which appears to have a respectable PageRank of 6.
I think Google goes overboard in considering the anchor text of links.
Another example is a search for "discount brokers" without thequotes. The top hit is a parked site, and the second is an empty directory that has been empty since at least November, and probably months before November. Total hits are 462,000.
Regards,
Daniel Brandt
---------------------------------------------------------------------
Public Information Research,
PO Box 680635, San Antonio TX 78268-0635
Nonprofit publisher of NameBase
http://www.namebase.org/
---------------------------------------------------------------------
Here is my immediate reply to him:
"Daniel,
thank you for your kind contact and my renewed compliments for your Good work on Google.
Thanks for bringing up this issue.
I must say that our duplicate domain issue baffles me as well and we have been wondering if to change our setup or not.
Problem is as follows:
We have started with the .org and .com domain pointing to the same folder on our server but problem is while we direct all traffic to the .org through the newsletter and our articles, over time Google has indexed a lot of the content as .com.
So I wouldn't know which would be the most appropriate step to take both from a technical viewpoint as well as from an ethical one.
Should I place a robots.txt limiting the visits of Googlebot only to the .org?
What is your personal advice?
Looking forward to your kind feedback,
Luigi Canali De Rossi"
Here are Daniel Brandt very interesting replies to me:
Luigi,
there is no easy solution.
I would never report your site or any site to Google, because I don't believe in helping them monopolize the web. But someone else might. And they do have duplicate-detection algorithms. It's not clear how well any of the old algorithms are working. You might be able to go a long time with two duplicate sites in Google.
You have more pages indexed in Google from .org than from .com, so you want to exclude Google from indexing your masternewmedia.com domain. A robots.txtfile for masternewmedia.com in the root directory like this should do it:
Here is how it should read:
User-agent: *
Disallow: /
That would exclude all spiders. They all have duplicate detection at some point, sooner or later, although sometimes I think that some of them have decided that duplicate detection is too much trouble.
This could take months, however. There is also a quicker way to clean masternewmedia.com out of Google. See the Google page about removing your site from their indexes.
The "urgent" removal mentioned in the middle of that page requires an email address for registration, and then you will get specific instructions. I suspect Google will ask for a robots.txt like this:
User-agent: googlebot
Disallow: /
That will take a couple of days to get your .com out of Google. Whatever they ask, follow their instructions. If they want a "User-agent: googlebot" then do it like they ask. After your site is purged, you may want to give it a couple of weeks and then change to User-agent: * That will take care of googlebot as well as other major spiders in the future.
Keep a record of everything you do if you go for the urgent removal. If Google screws up, the evidence that you tried to correct the problem will be evidence of good faith on your part, and you will have an easier time finding someone at Google to listen to you.
The problem with waiting and taking your chances with Google is that when they, sooner or later, decide to fix your duplicate problem, they may not dump the site you want them to dump.
One year ago, I had a duplicate doorway page on the NameBase site on two different domains. Google jumped the robots.txt on one of them because the URL was http://home.sprintmail.com/~pir/ (it was one of those "free web space" accounts) and Google does not ordinarily look for robots.txt except in the root directory. I had no access to the root directory and it didn't check my robots.txt. I should have known better.
Google came along and killed not only this doorway page, but also the same page on my main site! My traffic suffered for three months because the PageRank for thousands of deep pages came from the PageRank of the doorway. I removed the sprintmail site using Google's automatic removal system. It still took two months to get the doorway page indexed again on the main site.
In the old days, Google used to remove only the page with the lower PageRank and leave the other page. A year ago they were more drastic in their approach. I think they are less drastic now than they were a year ago, but this is still risky.
These days Google is very unpredictable, as you may know.
I would advise taking the urgent removal.
One problem with the urgent removal approach is that you will lose all of your backlink "juice." You cannot use a 301 redirect either, because a 301 will not transfer PageRank. Another approach would be to analyze your .com site in terms of where your backlinks are concentrated. Use Alltheweb for this; it is much better at showing backlinks.
Then overhaul the .com site with new content, and keep the old filenames that have most of the backlinks. This way the content is not duplicated, and you don't throw out those backlinks. This takes more work, of course.
You will probably be safe by making the content about 50 percent different between the two sites. In most cases, all you have to do is redistribute some small news items so that they are shuffled around to different pages. That way you can avoid duplicate-detection.
The duplicate detection is based on vector analysis. There's a certain threshold where it's considered a duplicate, and I don't know exactly where that is.
But if this looks like too much work, you may prefer the urgent removal. You should start emailing the sites that have backlinks to your .com and ask them to change the link to .org for the same page. Your success rate won't be high, but even if you get about 30 percent you will save a lot of your PageRank. This takes months also to regain.
Then the question is, if you intend to steer all of your backlinks so that they are concentrated at .org instead of .com, what possible justification is there for keeping the .com at all?
Webmasters will find it and link to it if it's there, and you'll lose the PageRank benefit of those future links if you have a robots.txt exclusion on the .com.
Good luck.
-- Daniel
I then wrote back to him one more time with this:
>Daniel, thank you for such a comprehensive and exhaustive answer.
>
>I am tempted even to edit it and publish it as it could be so helpful to many other people. Can you give me an OK?
>
>I have indeed a scattered bunch of linkers on both sides and I am thorn on what to do with that. But you know what I think? > I am also attempting a kamikaze operation and betting my referrals all on direct and recommended links instead of
> search engine referred visitors: Becoming Google-independent.
>
> One year ago I had almost 80% of my traffic coming from Google, now it is almost perfectly reversed: 70% direct referrals > and 30% from search engines. isn't that what anyone in his own right mind would want?
>
> What is more valuable: 1000 visitors from Google or 1000 visitors from directly referred links?
>
>Looking forward to your kind feedback,
>
>Luigi
Daniel's final reply:
"Luigi,
everyone yearns for Google independence these days. Google has been making webmasters very nervous. If you have less than 30 percent of your traffic from search engines, I wouldn't worry about Google penalizing you for duplicate content. I envy you. My goal too is Google-independence.
-- Daniel
If you are interested by the exchange reported above check out the latest article on Google overwhelming prowess just scouted by the great guys at Google-Watch.org: is called "Is Google God?" by New York Times columnist Thomas L. Friedman.
Hats for excellent insight, reporting and research content. The way to go.